Conţinut
- Definiție - Ce înseamnă Web Crawler?
- O introducere în Microsoft Azure și Microsoft Cloud | În acest ghid, veți afla despre ce este vorba despre cloud computing și despre cum Microsoft Azure vă poate ajuta să migrați și să conduceți afacerea din cloud.
- Techopedia explică Web Crawler
Definiție - Ce înseamnă Web Crawler?
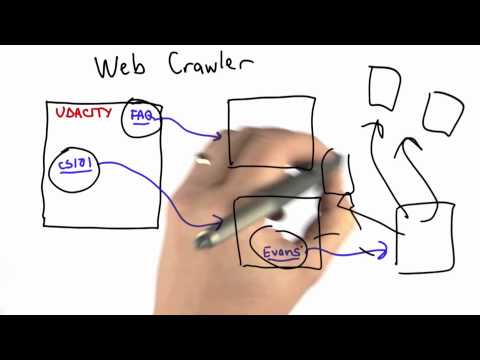
Un crawler Web este un bot de internet care ajută la indexarea Web. Acestea parcurg o pagină pe rând prin intermediul unui site web până când toate paginile au fost indexate. Crawler-urile web ajută la colectarea informațiilor despre un site web și link-urile aferente acestora și, de asemenea, ajută la validarea codului HTML și a hyperlink-urilor.
Un crawler Web este cunoscut și sub numele de spider Web, indexator automat sau pur și simplu crawler.
O introducere în Microsoft Azure și Microsoft Cloud | În acest ghid, veți afla despre ce este vorba despre cloud computing și despre cum Microsoft Azure vă poate ajuta să migrați și să conduceți afacerea din cloud.
Techopedia explică Web Crawler
Crawler-urile web colectează informații precum adresa URL a site-ului web, informațiile meta tag, conținutul paginii Web, link-urile din pagina web și destinațiile care conduc de la aceste link-uri, titlul paginii web și orice alte informații relevante. Ei urmăresc adresele URL care au fost deja descărcate pentru a evita din nou descărcarea aceleiași pagini. O combinație de politici precum politica de re-vizită, politica de selecție, politica de paralelizare și politica de politețe determină comportamentul crawlerului web. Există multe provocări pentru crawler-urile web, și anume World Wide Web mare și în continuă evoluție, compromisuri de selecție de conținut, obligații sociale și relaționarea cu adversarii.
Crawler-urile web sunt componentele cheie ale motoarelor și sistemelor de căutare web care se uită în paginile web. Acestea ajută la indexarea intrărilor Web și permit utilizatorilor să interogheze împotriva indexului și furnizează, de asemenea, paginile web care se potrivesc cu interogările. O altă utilizare a crawler-urilor Web este în arhivarea Web, care implică seturi mari de pagini web care trebuie colectate și arhivate periodic. Crawler-urile web sunt de asemenea utilizate în exploatarea datelor, în care paginile sunt analizate pentru diferite proprietăți, cum ar fi statisticile, iar analiza datelor este apoi efectuată pe acestea.